HEAT on the DEC AlphaServer 8400
HEAT is the 3-D heat diffusion kernel of RAGE.
The DEC AlphaServer 8400 is a shared-memory multiprocessor compute server. The LANL machine, turbolaser, comprises twelve EV5 (second-generation DEC ALPHA) processors, each with an 8Kb on-chip cache (L1), approx 100Kb on-chip cache (L2), 4MB off-chip cache (L3), and ??MB shared system memory, running OSF1 V3.2.
HEAT was run on problems of various sizes ranging from 1 (cubed) to 80 (cubed), on a number of processors ranging from 1 to 11. Since dedicated use of the machine was not possible, each combination of problem size and number of processors was run approximately fifty times and the resulting performance figure taken to be the best over all runs.
Parallelism was achieved using Kuck and Associates kapf source-to-source optimizing Fortran preprocessor, using programmer-supplied annotations to introduce parallelism at appropriate points.
The performance data consists of a number of triples, each giving a number of processors, size of problem, and a FLOPS value--the total number of floating-point operations over the best (shortest) observed wall-clock time. This data is presented in three formats.
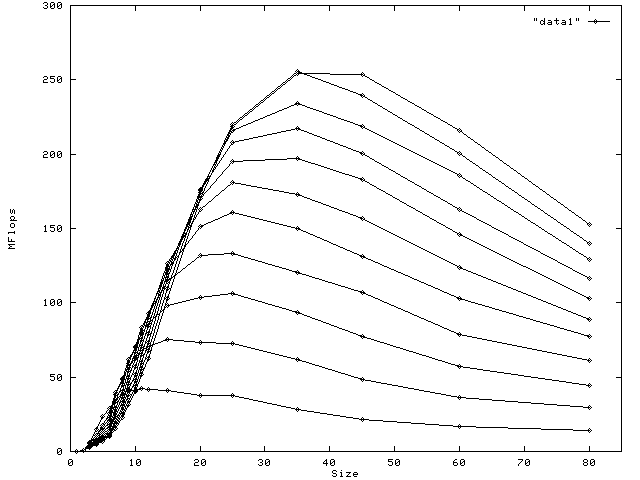
The first graph, shown above, plots MFLOPS as a function of problem size, one curve for each number of processors--the overall lowest curve represents one processor, the highest, eleven. Three observations can be made:
- asymptotically in problem size, performance becomes roughly linear in the number of processors;
- peak performance is reached at larger problem sizes for larger numbers of processors, beyond which performance declines in all cases for larger problem sizes;
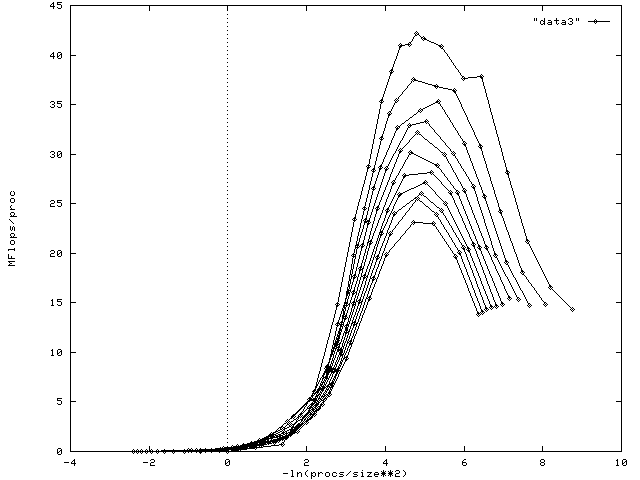
- at smaller problem sizes using fewer processors may give better performance.
The second graph, shown below, plots MFLOPS per processor as a function of problem size; here the line with the highest peak corresponds to one processor, the lowest for eleven.
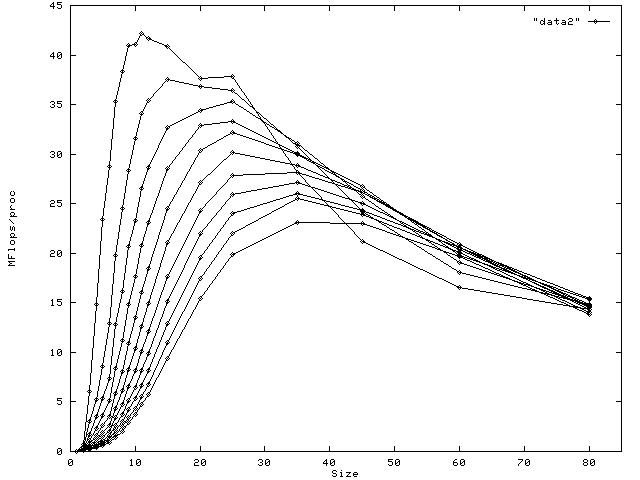
Both of these graphs make clear that for any fixed number of processors, beyond a certain problem size performance declines monotonically, and that the greater the number of processors, the greater the problem size at which this decline begins. We hypothesise that this is a consequence of cache usage: beyond a certain problem size the effect of cache spillage becomes increasingly pronounced. As can be seen from the second graph, as the curves cross as problem size increases, this has the curious effect of giving, as a function of the number of processors, super-linear speedup. In support of this hypothesis we present the data in a third format below. Roughly, the idea is to normalise the curves in the second graph with respect to the actual problem size seen by each processor. To this effect we scale the x value of each point by the number of processors divided by the nominal problem size cubed (recall that the nominal problem size is the length of each dimension of a three dimensional matrix). As expected the peaks in the curves are very close to alignment.